4. Quelques applications pratiques des méthodes de statistique non paramétrique
4.1. Cas d'un échantillon isolé
Des tests permettent de vérifier si un échantillon observé peut être considéré comme extrait d'une population donnée (Test d'ajustement). Ces tests peuvent permettre de répondre aux questions suivantes :
- - Y a t-il une différence significative de localisation (tendance centrale) entre l'échantillon et la population ?
- - Y a t-il une différence significative entre les fréquences observées et les fréquences
attendues sur la base d'un principe ?
- - Y a t-il une différence significative entre des proportions observées et des proportions espérées?
- - Est-il raisonnable de penser que cet échantillon a été tiré d'une population d'une forme particulière ?
- - Est-il raisonnable de penser que cet échantillon est un échantillon d'une certaine population connue ?
4.1.1. Test binomial
Test d'ajustement. Il y a des populations où seulement deux classes sont distinguées : mâle et femelle; lettré et illéttré... Dans un tel cas, toutes les observations de cette population tomberont dans l'une ou l'autre classe. Pour toutes ces populations, si nous connaissons la proportion des cas d'une classe (P), nous connaissons celle de l'autre classe (1-P=Q). Ces proportions sont fixées pour une population donnée. Cependant, ces proportions exactes ne se retrouverons pas dans un échantillon prélevé au hasard dans cette population. De telles différences entre les valeurs observées et celles de la population sont dues au processus d'échantilonnage. Bien entendu, de faibles différences sont plus probables que de fortes différences. Le test binomial nous permet de dire si il est raisonnable de penser que les proportions (ou fréquences) observées dans notre échantillon proviennent d'une population ayant une valeur donnée de P.
Méthode
La loi binomiale ne dépend que d'un paramètre, la probabilité p de "l'événement favorable". La probabilité d'obtenir x objets dans une catégorie et N-x dans une autre est donné par la formule :
p (x) = (N!/x! (N-x)!) Px QN-x
N= nombre d'observations; P= proportion de cas attendus dans une catégorie ;
Q = 1-P = proportion de cas attendus dans l'autre catégorie.
Nous pouvons alors répondre à la question suivante : quelle est la probabilité exacte d'obtenir les valeurs observées. Mais le plus souvent nous posons la question : Quelle est la probabilité d'obtenir les valeurs observées ou des valeurs encore plus extrêmes ? La distribution d'échantillonnage est alors
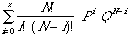 | (1) |
Exemple :
Quelle est la probabilité d'obtenir deux six ou moins de deux six après cinq jets d'un dé non pipé ?
| N= 5 (le nombre de jets) ; | x = 2 (le nombre de six) ; | P = 1/6 (proportion de six attendue) ; |
| Q = 5/6. |
p (>= 2) probabilité d'obtenir deux ou moins de deux six = p (0) + p (1) + p (2)
p (0) probabilité d'obtenir zéro six; p (1) probabilité d'obtenir un six;
p (2) probabilité d'obtenir deux six.
p (0) = (5!/0!5!) (1/6)0 (5/6)5 = 1 x 1 x 0,40 = 0,40
p (1) = (5!/1!4!) (1/6)1 (5/6)4 = 5 x 0,1666 x 0,4822 = 0,40
p (2) = (5!/2!3!) (1/6)2 (5/6)3 = 10 x 0,0277 x 0,578 = 0,16
p (x 2) = p (0)+ p (1)+ p (2) = 0,40 + 0,40 + 0,16 = 0,96
La probabilité d'obtenir sous H0 deux six ou moins lorsqu'un dé non pipé est lancé cinq fois est p = 0,96.
Petits échantillons
Dans le cas d'un échantillon à deux classes, une situation commune est celle où P = 1/2. Lorsque l'effectif est inférieur à 25, la table 3 donne les probabilités associées à diverses valeurs de x (la plus petite des fréquences observées) pour différents effectifs N (de 5 à 25).
Lorsque P est différent de Q, la formule précédente doit être utilisée.
Exemple :
Dans une étude des effets du stress, on enseigne à 18 étudiants deux méthodes différentes de faire un noeud. La moitié des sujets (choisie au hasard dans le goupe de 18) apprend d'abord la méthode A, puis la méthode B. L'autre moitié apprend en premier la méthode B, puis la méthode A. Après avoir subi un examen de quatre heures, on demande à chaque sujet de faire le noeud. L'hypothèse est que le stress induit une régression, c'est-à-dire, que les sujets utiliserons la première méthode apprise. Chaque sujet
est catégorisé suivant qu'il utilise la première méthode apprise ou la seconde après le stress.
Hypothèse nulle
H0 : p1 = p2 = 1/2
Il n'y a pas de différence entre la probabilité d'utiliser la première méthode apprise (p1) et celle d'utiliser la seconde méthode apprise (p2), après le stress.
H1 : p1 > p2 unilatéral
Test statistique
Le test binomial est choisi car les données rentrent dans deux catégories discrètes et l'échantillon est unique. L'apprentissage en premier ou second des deux méthodes A et B étant reparti au hasard, il n'y a pas de raison de penser que la première méthode apprise soit préférée à la seconde, compte tenu de H0, et de P = Q = 1/2.
Niveau de signification
a = 0,01 et N = 18
Distribution d'échantillonnage
Comme N < 25 et P = Q = 1/2, la table 3 donne la probabilité associée des valeurs observées de x.
Région de rejet
Elle comprend toutes les valeurs de x (nombre de sujets qui ont utilisé, après le stress, la seconde méthode apprise) qui
sont si faibles que leur probabilité associée sous H0 est égale ou inférieure à a = 0,01. Comme la direction de la différence est prédite d'avance, le test est unilatétral.
Décision
Dans cette expérience les résultats obtenus après le stress sont les suivants :
| Méthode choisie
|
|---|
| Première apprise | Deuxième apprise | Total
|
| Fréquence | 16 | 2 | 18 |
|---|
N = nombre d'observations indépendantes = 18
x = la fréquence la plus faible
La Table 3 montre que pour N = 18, la probabilité associée avec x 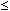 2 est p = 0,001. Attendu que cette probabilité est inférieure à a = 0,01, nous pouvons rejeter H0 en faveur de H1. Nous concluons que p1 > p2, c'est-à-dire, les personnes soumises à un stress utilisent la première des deux méthodes apprises.
2 est p = 0,001. Attendu que cette probabilité est inférieure à a = 0,01, nous pouvons rejeter H0 en faveur de H1. Nous concluons que p1 > p2, c'est-à-dire, les personnes soumises à un stress utilisent la première des deux méthodes apprises.
Grands échantillons
lorsque N est supérieur à 25, la table 3 ne peut être utilisée. Cependant, lorsque N s'accroît, la distribution binomiale
tend vers la distribution normale. Cette tendance rapide lorsque P est proche de
0,5, se ralentie lorsque P est voisin de 0 ou de 1. Donc, plus la disparité entre
P et Q est importante, plus l'échantillon devra être important pour que l'approximation soit utile. Dans ce cas, une méthode empirique indique que NPQ doit être égal au moins à 9 avant que le test basé sur l'approximation normale soit applicable. La distribution normale est utilisée pour des variables continues, alors que la distribution binomiale implique des variable discrètes, pour que l'approximation soit excellente une correction pour la continuité doit être incorporée. Compte tenu de ces contraintes, Ho peut être testée par la formule
z = ((x 0,5) - NP) / > > | (2) |
On utilisera x + 0,5 lorsque x < NP et x
- 0,5 lorsque x > NP.
La signification du z obtenu peut être déterminée par référence à la table 1, qui donne, pour les tests unilatéraux, la probabilité associée d'obtenir, sous H0,
des valeurs aussi extrêmes que celle du z (Pour les tests bilatéraux, la probabilité de la table doit être doublée).
Reprenons l'exemple précédent :
x< NP (2 < 9) la formule est
z = (2 + 0,5) - (18) (0,5) / 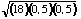 = 2,5 - 9 / 2,1213
= 2,5 - 9 / 2,1213
z = - 3,07
La Table 1 montre qu'un tel z a une probabilité associée à son occurence sous H0 de p = 0,0011. Nous avons trouvé à peu près la même probabilité avec la table des probabilités exactes, ce qui montre la qualité de l'approximation.
Résumé de la procédure
- Déterminer le nombre total d'observations = N.
- Déterminer les fréquences observées dans chacune des deux catégories.
- Si N est égal ou inférieur à 25
- a- Et si P = Q = 0,5, utiliser directement la table 3 pour les tests unilatéraux. Pour les tests bilatéraux, il faut doubler le p
de la table 3.
- b- Et si P = Q, utiliser la formule (1) et se reporter la table 3.
- Si N est supérieur à 25 et P voisin de 0,5, utiliser la formule
(2) et se reporter à la table 1.
Si la probabilité p associée à la valeur observée x ou à une valeur plus extrême est égal ou inférieure à a, rejeter H0.
Il n'existe pas d'alternative à ce test.
4.1.2. Test du Khi carré d'ajustement (Chi square one-sample test)
Le chercheur peut être intéressé par le nombre de sujets, d'objets ou de réponses qui se répartissent dans différentes catégories. Par exemple, il est possible de classer des enfants suivant leurs jeux, ou des personnes suivant qu'elles sont "favorables à", "indifférentes" ou "opposées à" une opinion donnée et de tester l'hypothèse selon laquelle ces jeux ou ces réponses diffèrent entre eux par leur fréquence.
Le nombre de classes peut être de deux ou plus. C'est un test d'ajustement puisque nous comparons un nombre observé d'objets ou de réponses dans chaque classe à un nombre espéré sur la base de l'hypothèse nulle.
Méthode
L'hypothèse nulle fixe la proportion d'objets dans chaque classe de la population théorique (fréquences attendues ou théoriques). Le test du khi carré (c2) vérifie si les fréquences observées sont suffisamment proches des fréquences attendues pour représenter la population théorique.
On peut démontrer que
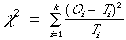 | (3) |
où
Oi = fréquence observée dans chaque classe
i = somme des k classes
Ti = fréquence théorique dans chaque classe i
La valeur du Khi carré observée est nulle lorsque les fréquences observées sont toutes égales aux fréquences attendues, c'est-à-dire lorsqu'il y a concordance absolue entre la distribution observée et la distribution théorique. Cette valeur est d'autant plus grande que les écarts entre les fréquences observées et attendues sont plus grands.
La signification de la valeur observée se fait par référence à la table 2. On rejettera l'hypothèse nulle lorsque la probabilité associée à la valeur observée, pour un degré de liberté = k -1, est égale ou inférieure à 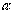 .
.
Exemple
Ségrégation de la descendance d'un dihybride de Pisum sativum. Parmi 556 plantes, Mendel a observé 315 individus à graines rondes et albumen jaune (classe 1), 108 individus à graines rondes et albumen vert (classe 2), 101 individus à graines anguleuses et albumen jaune (classe 3) et 32 individus à graines anguleuses et albumen vert (classe 4). Ces fréquences observées sont-elles compatibles avec l'hypothèse d'une ségrégation 9/3/3/1 ?
Hypothèse nulle
| H0 : | P1 = 9/16 | P2 = P3 = 3/16 | P4 = 1/16 |
et les fréquences attendues sont :
- T1 = 556 (9/16) = 312,75
- T2 = T3 = 556 (3/16) = 104,75
- T4 = 556 (1/16) = 34,75
Test statistique
Le test du khi carré est choisi car nous voulons comparer les fréquences observées dans des classes discrètes et leurs fréquences attendues. Nous avons ici quatre classes.
Niveau de signification
a = 0,01 et N = 556.
Distribution d'échantillonnage
Calculer d'après la formule (3) . Le degré de liberté est de k -1 = 3
Région de rejet
H0 sera rejetée si la valeur observée du khi carré est telle que sa probabilité associée, sous H0, avec ddl = 3 est égale ou inférieure à a = 0,01.
Décision
Les résultats sont présentés dans le tableau suivant :
| Classe 1 | Classe 2 | Classe 3 | Classe 4
|
|---|
| Fréquences théoriques | 312,75 | 104,25 | 104,25 | 34,75
|
|---|
| Fréquences observées | 315 | 108 | 101 | 32 |
|---|
Le calcul est
c2 = (315 - 312,75)2/312,75 + (108 -104,25)2/104,25 + (101 - 104,25)2/104,25 + (32 - 34,75)2/34,75
c2 = 2,252/312,75 + 3,752/104,25 + 3,252/104,25 + 2,752/34,75
c2 = 0,470
La Table 2 montre que le khi carré = 0,47 pour un ddl = 3 a une probabilité d'apparition comprise entre 0,95 et 0,90. Comme cette probabilité est largement supérieure au seuil de signification choisi a = 0,01, nous ne pouvons rejeter l'hypothèse nulle.
Une condition doit être respectée (car le résultat obtenu n'est qu'approché) pour que le résultat soit considéré comme satisfaisant : toutes les fréquences attendues doivent être au moins égale à 5 lorsque le degré de liberté est égal à 1 ou plus de 20% des fréquences attendues ne peuvent être inférieures à 5 et aucune inférieure à 1 lorsque le degré de liberté est supérieur à 1. Quand cette condition n'est pas remplie, on peut regrouper dans certains cas des classes voisines, de manière à augmenter les fréquences attendues.
Quand les données sont mesurées dans une échelle nominale ou quand elles sont constituées de fréquences classées de façon discrète, il n'existe pas d'autres alternatives à ce test. Si le degré de liberté est supérieur à 1, le khi carré est insensible aux effets d'ordre, aussi si l'hypothèse prend en compte l'ordre des fréquences, ce test n'est pas le meilleur.
4.1.3. Test de Kolmogorov et Smirnov (Kolmogorov-Smirnov one-sample test)
C'est un test d'ajustement. Il détermine si les observations d'un échantillon peuvent raisonnablement provenir d'une population théorique donnée. Il est basé sur la comparaison
de la fonction cumulative de fréquences (N (x)) de l'échantillon et de celle (F(x)) de la population donnée. La plus grande divergence, en valeur absolue, existant entre ces deux distributions est recherchée. La référence à la distribution d'échantillonnage indique si une telle différence est vraisemblable sur la base du hasard.
Méthode
D = maximum 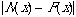 | (4) |
La distribution d'échantillonnage de D est connue. La table 4 en donne certaines valeurs critiques. La signification d'une valeur donnée de D dépend de la taille de l'échantillon N. La table 4 ne donne que les valeurs critiques de D pour N compris de 1 à 35. Au-delà de N = 35, on détermine les valeurs critiques de D par les divisions indiquées dans la table 4. Par exemple, lorsque l'on travaille avec un échantillon de 43 observations et que
l'on a fixé a = 0,05, la table 4 montre que tout D égal ou supérieur à 1,36 /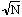 sera significatif. Ainsi, tout D,
calculé par la formule (4), égal ou supérieur à 1,36 /
sera significatif. Ainsi, tout D,
calculé par la formule (4), égal ou supérieur à 1,36 /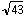 = 0,207 sera significatif au seuil 0,05 pour un
test bilatéral.
= 0,207 sera significatif au seuil 0,05 pour un
test bilatéral.
Exemple
Existe-t-il une hiérarchie des préférences parmi les teintes de peau ? Un chercheur fictif prend la photographie de 10 personnes. Il les fait développer de telle sorte qu'il obtient cinq copies ou épreuves photographiques de chaque personne. Chaque copie diffère légérement des autres de façon à pouvoir les ranger de la plus sombre à la plus claire. La photo représentant la plus sombre est numérotée 1, la suivante 2 et la plus claire 5. Chaque sujet choisit parmi ces cinq copies de son visage, celle qu'il préfère. Si la teinte de la peau n'a pas d'importance pour les sujets, les copies seront choisies aléatoirement selon leur rang. Si la teinte de la peau a de l'importance, les sujets choisiront les copies extrêmes.
Hypothèse nulle
H0 : on ne peut s'attendre à aucune différence dans le choix des copies en fonction de leur rang.
H1 : les fréquences de choix des différentes copies ne sont pas égales.
Test statistique
Le test Kolmogorov-smirnov est choisi car on cherche à comparer la distribution des scores observés (mesurés dans une échelle de rangement) à celle d'une distribution théorique.
Niveau de signification
a = 0,01. Le nombre de sujets étudiés N = 10.
Distribution d'échantillonnage
Des valeurs critiques de D de la distribution d'échantillonnage sont présentées dans la table 4, avec leurs probabilités d'occurence sous H0.
Région de rejet
Elle comprend toutes les valeurs de D calculée qui sont si fortes que la probabilité associée avec leur obtention, sous H0, est égale ou inférieure à a = 0,01.
Décision
Dans notre étude hypothétique, un sujet a choisi l'épreuve 2, cinq autres sujets l'épreuve 4 et quatre autres l'épreuve 5. Ces données sont dans le tableau suivant :
| Rang des épreuves choisies
|
|---|
| 1 | 2 | 3 | 4 | 5
|
|---|
| Fréquence des sujets ayant choisi ce rang | 0 | 1 | 0 | 5 | 4
|
|---|
F (x) distribution cumulative théorique
des choix sous H0 | 1/5 | 2/5 | 3/5 | 4/5 | 5/5
|
|---|
N(x) distribution cumulative des choix
observés | 0/10 | 1/10 | 1/10 | 6/10 | 10/10
|
|---|
| N (x) - F (x) | 2/10 | 3/10 | 5/10 | 2/10 | 0 |
|---|
Ce tableau révèle que D = 5/10 = 0,500. La table 4
montre que pour N = 10,
D > 0,500 a une probabilité associée, sous H0, de p < 0,01. Comme p est inférieur à = 0,01, notre décision est de rejeter H0 dans cette étude hypothétique. Nous concluons que les sujets étudiés montrent des préférences significatives parmi
les teintes de peau.
Ce test traite les observations individuelles séparément et ne nécessite en aucun cas la combinaison de classes comme dans le khi carré. De plus ce test est utilisable avec de petits échantillons, contrairement au khi carré.
Aussi le test de Kolmogorov-Smirnov est dans tous les cas plus puissant que le test
du khi carré.
4.4. Discussion
Pour tester des hypothèses concernant le tirage d'un échantillon d'une population avec une distribution donnée, nous devons utiliser l'un des trois tests d'ajustement présentés. Le choix parmi ces trois tests se détermine par :
1. le nombre de catégories observées ; 2. l'échelle de mesure utilisée ; 3. la taille de l'échantillon et 4. la puissance du test.
Le test binomial peut être utilisé lorsque les données sont classées seulement en deux catégories. Mais il n'est intéressant que lorsque la taille de l'échantillon est trop faible pour permettre l'emploi du khi carré.
Le khi carré doit être utilisé lorsque les données se rangent dans des catégories discrètes et lorsque les fréquences attendues sont suffisamment importantes.
Ces deux tests peuvent être mis en oeuvre lorsque les données sont mesurées dans une échelle nominale ou de rangement.
Le test de Kolmogorov-Smirnov doit être utilisé quand la variable considérée a une distribution continue. Mais dans le cas contraire, appliqué à une variable discontinue, si H0 est rejetée, nous pouvons avoir confiance en cette décision. Comme ce test
ne nécessite aucun groupement des données et qu'il permet de traiter des échantillons de faible taille, chaque fois que ces conditions sont remplies, il est le plus puissant des tests d'ajustement présentés.
Le test des séquences (one-sample runs test) est concerné par la distribution au hasard des séquences des événements dans un échantillon. Cette méthode est basée sur l'ordre ou la séquence dans lequel les observations
individuelles ont été obtenues. Ce test n'a pas de test paramétrique alternatif.


