Le plus souvent nous disposons de différents tests pour une recherche (validation d'hypothèse) donnée, il est alors nécessaire d'employer une méthode rationnelle pour choisir le test le plus approprié.
Nous avons vu que l'un des critères de choix est la puissance du test utilisé. Mais d'autres critères sont importants pour déterminer l'adéquation d'un test lors de l'analyse de données particulières. Ces critères concernent :
la façon dont l'échantillon a été réalisé,
la nature de la population de laquelle a été tiré l'échantillon et
Lorsque nous définissons la nature de la population et le mode d'échantillonnage, nous établissons un modèle statistique (c'est à dire une formulation mathématique des hypothèses faites sur les observations). A chaque test statistique est associé un modèle et des contraintes de mesure. Ce test n'est alors valide que si les conditions imposées
par le modèle et les contraintes de mesure sont respectées. Il est difficile de dire si les conditions d'un modèle sont remplies, et le plus souvent nous nous contentons d'admettre qu'elles le sont. Aussi devrions nous préciser, chaque fois : "Si le modèle utilisé et le mode de mesure sont corrects, alors....).
Il est clair que moins les exigences imposées par le modèle sont nombreuses et restrictives, plus les conclusions que l'on tire sont générales.
De ce fait, les tests les plus puissants sont ceux qui ont les hypothèses les plus
strictes. Si ces hypothèses sont valides, ces tests sont alors les mieux à même de rejeter H0 quand elle est fausse et de ne pas rejeter H0 quand elle est vraie.
Exemple : Le test de t (test paramétrique) est un des tests statistiques les plus
puissants. Mais avant d'accepter les conclusions d'un tel test, nous devons vérifier que ses conditions d'utilisations sont remplies. Ces conditions sont les suivantes :
Les observations doivent être indépendantes. La sélection d'une observation pour un échantillon ne doit pas biaiser les chances de sélectionner une autre observation pour cet échantillon. [Pour que l'indépendance des observations soit respectée, il faut :
* dans le cas du tirage d'une boule dans une urne contenant des boules noires
et des blanches dans certaines proportions, ou de cartes dans un jeu de cartes à
jouer, il faut remettre boule et carte dans l'ensemble de départ et brasser soigneusement l'ensemble
** sinon considérer que l'on a affaire à une urne illimitée contenant un nombre tellement gand de boules que l'extraction d'une ne modifie pratiquement pasles proportions données]
Les observations doivent être tirées de populations normales (exemple : courbe de Gauss ou courbe normale réduite).
Ces populations doivent avoir la même variance (condition d'homoscédasticité; Homoscedasticity). La validité de cette hypothèse peut être contrôlée à l'aide des tests d'égalité de variance.
Les variables doivent être mesurées dans une échelle de mesure permettant l'utilisation des opérations arithmétiques.
A part l'hypothèse d'homoscédasticité, qui peut être testée, les autres hypothèses sont considérées comme vraies.
Quand les hypothèses constituant le modèle statistique d'un test ne sont pas remplies, il est alors difficile de dire quel est le pouvoir réel du test et d'estimer la signification de son résultat.
Il est donc très important de considérer la nature des données (observations) que l'on va tester. D'elle dépend la nature des opérations possibles et donc des statistiques
utilisables dans chaque situation.
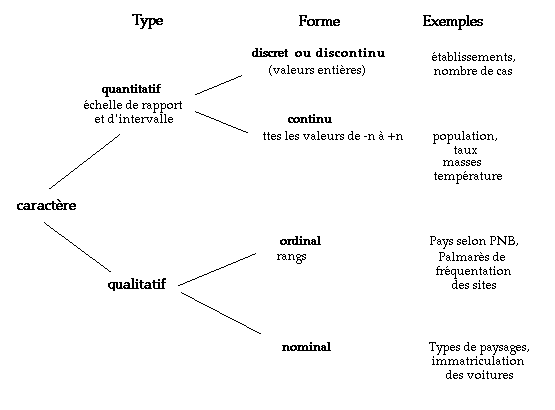
Les observations peuvent être soit quantitatives soit qualitatives.
Les données quantitatives comprennent les dénombrements (ou comptages) et les mesures (ou mensurations).
Dans le cas des dénombrements, la caractéristique étudiée est une variable discrète ou discontinue, ne pouvant prendre que des valeurs entières non négatives (nombre
de fruits par rameau, nombre de pétales par fleurs, nombre de tête de bétail..). Il suffit de compter le nombre d'individus affectés par chacune des valeurs (fréquences) de la variable.
exemple : nombre de pétales par fleurs dans un échantillon de 1000 fleurs de Renonculus repens (Vessereau, 1948)
Nombre de pétales par fleur
3
4
5
6
7
Nombre de fleurs (Fréquences)
1
20
959
18
2
Dans le cas des mesures, la variable est de nature continue (hauteur, poids, surface,
concentration, température..). Les valeurs possibles sont illimités mais du dait des méthodes de mesures et du degré de précision de l'appareil de mesure, les données varient toujours de façon discontinue.
Les mensurations peuvent être réalisées dans deux échelles de mesure : l'échelle de rapport et l'échelle d'intervalle. Elles sont manipulables suivant les opérations de l'arithmétique.
L'échelle de rapport est caractérisée par l'existence d'un zéro absolu et de distances de taille connue entre deux valeurs quelconque de l'échelle. C'est le cas de la mesure de la masse ou du poids. En effet, les échelles de mesure des poids en pounds ou en grammes ont toutes deux un zéro absolu et le rapport entre deux poids quelconque d'une échelle est indépendant de l'unité de mesure (le rapport des poids de deux
objets mesurés en pounds et celui de ces mêmes objets mesurés en grammes sont identiques).
Dans l'échelle d'intervalle, le point zéro et l'unité de mesure sont arbitraires mais les distances entre deux valeurs quelconques de l'échelle sont de taille connue.
C'est le cas de la mesure de la température (échelle Fahrenheit ou Celsius). Ces deux échelles sont compatibles avec l'utilisation de tests paramétriques.
Les données qualitatives peuvent être assimilées au cas des variables discontinues, en supposant que les différentes variantes du caractère qualitatif sont rangées dans un ordre correspondant par exemple à la suite des nombres entiers positifs (différentes couleurs, différents degrés d'infection...).
Les données qualitatives peuvent être réalisées dans deux échelles de mesure : échelle de rangement et l'échelle nominale. Ces données ne sont pas manipulables par l'arithmétique.
Dans l'échelle ordinale (de rangement), il existe une certaine relation entre les
objets du type plus grand que, supérieur à, plus difficile que, préférée à....
Exemple : Les nombres de candidats à un examen obtenant les degrés A, B, C. Le degré A est meilleur que le degré B, lui-même meilleur que le degré C. Une transformation ne changeant pas l'ordre des objets est admissible. La statistique la plus appropriée pour décrire la tendance centrale des données est la médiane.
Dans l'échelle nominale, les nombres ou symboles identifient les groupes auxquels divers objets appartiennent. C'est le cas des numéros d'immatriculation des voitures ou de sécurité sociale (chaînes de caractères). Le même nombre peut être donné aux
différentes personnes habitant le même département ou de même sexe constituant des sous-classes. Les symboles désignant les différentes sous-classes dans l'échelle nominale peuvent
être modifiés sans altérer l'information essentielle de l'échelle. Les seules statistiques descriptives utilisables dans ce cas sont le mode, la fréquence... et les tests applicables seront centrés sur les fréquences des diverses catégories.
Ces deux dernières échelles ne permettent que l'utilisation de tests non paramétriques.
Un test paramétrique requiert un modèle à fortes contraintes (normalité des distributions, égalité des variances) pour lequel les mesures doivent avoir été réalisées dans une
échelle au moins d'intervalle. Ces hypothèses sont d'autant plus difficiles à vérifier que les effectifs étudiés sont plus réduits.
Un test non paramétrique est un test dont le modèle ne précise pas les conditions que doivent remplir les paramètres de la population dont a été extrait l'échantillon.
Cependant certaines conditions d'application doivent être vérifiées. Les échantillons considérées doivent être aléatoires [lorsque tous les individus ont la même probabilité de faire partie de l'échantillon] et simples [tous les individus qui doivent former l'échantillon sont prélevés indépendamment les uns des autres] (7), et éventuellement indépendants les uns des autres [emploi de tables de nombres aléatoires]. Les variables aléatoires prises en considération sont généralement supposées continues.
Leur emploi se justifie lorsque les conditions d'applications des autres méthodes ne sont pas satisfaites, même après d'éventuelles transformation de variables.
Les probabilités des résultats de la plupart des tests non paramétriques sont des probabilités exactes quelle que soit la forme de la distribution de la population dont est tiré l'échantillon.
Pour des échantillons de taille très faible jusqu'à N = 6, la seule possibilité est l'utilisation d'un test non paramétrique, sauf si la nature exacte de la distribution de la population est précisément connue. Ceci permet une diminution du coût ou du temps nécessaire à la collecte des informations.
Il existe des tests non paramétriques permettant de traiter des échantillons composés à partir d'observations provenant de populations différentes. De telles données ne peuvent être traitées par les tests paramétriques sans faire des hypothèses irréalistes.
Seuls des tests non paramétriques existent qui permettent le traitement de données qualitatives : soit exprimées en rangs ou en plus ou moins (échelle ordinale), soit nominales.
Les tests non paramétriques sont plus facile à apprendre et à appliquer que les tests paramétriques. Leur relative simplicité résulte souvent du remplacement des valeurs observées soit par des variables alternatives, indiquant l'appartenance à l'une ou à l'autre classe d'observation, soit par les rangs, c'est-à-dire les numéros d'ordre
des valeurs observées rangées par ordre croissant. C'est ainsi que la médiane est généralement préférée à la moyenne, comme paramètre de position.
Les tests paramétriques, quand leurs conditions sont remplies, sont les plus puissants que les tests non paramétriques.
Un second inconvénient réside dans la difficulté a trouver la description des tests et de leurs tables de valeurs significatives, surtout en langue française. Heureusement, les niveaux de significativité sont donnés directement par les logiciels statistiques courants.
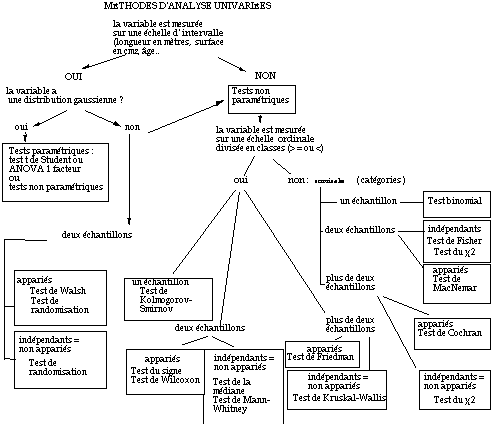
On choisira les tests appropriés en fonction du type de mesure, de la forme de la
distribution de fréquences et du nombre d'échantillons dont on dispose (voir schéma).
L'assistance de logiciels statistiques permet d'effectuer rapidement et avec une bonne
fiabilité les calculs nécessaires à l'authentification des tests et à obtenir les paramètres nécessaires pour accepter ou rejeter les hypothèses. Il s'agit :
LOGICIELS STATISTIQUES
MacOS
MS DOS
Statview
+
+
Systat
+
+
Statlab
+
+
PCSM
+
Unistat
+
ViSta
+
+
ADE Analyse des données écologiques
+
+
Vous pouvez aussi consulter le Pôle Bio-informatique Lyonnais.
Ces différents logiciels comportent les mêmes tests de base avec un plus ou moins grand nombre de tests supplémentaires. Ce qui les distingue est leur prix, leur facilité d'emploi et la plus ou moins grande diversité des tests proposés.